Abstract
GPUs are increasingly utilized for running DNN tasks on emerging mobile edge devices. Beyond accelerating single task inference, their value is also particularly apparent in efficiently executing multiple DNN tasks, which often have strict latency requirements in applications. Preemption is the main technology to ensure multitasking timeliness, but mobile edges primarily offer two priorities for task queues, and existing methods thus achieve only coarse-grained preemption by categorizing DNNs into real-time and best-effort, permitting a real-time task to preempt best-effort ones. However, the efficacy diminishes significantly when other real-time tasks run concurrently, but this is already common in mobile edge appli- cations. Due to different hardware characteristics, solutions from other platforms are unsuitable. For instance, GPUs on traditional mobile devices primarily assist CPU processing and lack special preemption support, mainly following FIFO in GPU scheduling. Clouds handle concurrent task execution, but focus on allocating one or more GPUs per complex model, whereas on mobile edges, DNNs mainly vie for one GPU. This paper introduces Pantheon, designed to offer fine-grained preemption, enabling real-time tasks to preempt each other and best-effort tasks. Our key observation is that the two-tier GPU stream priorities, while underexplored, are sufficient. Efficient preemption can be realized through software design by innovative scheduling and novel exploitation of the nested redundancy principle for DNN models. Evaluation on a diverse set of DNNs shows substantial improvements in deadline miss rate and accuracy of Pantheon over state-of-the-art methods.
System Overview
Figure 1 shows the Pantheon design that works between the deep learning framework and the applications.
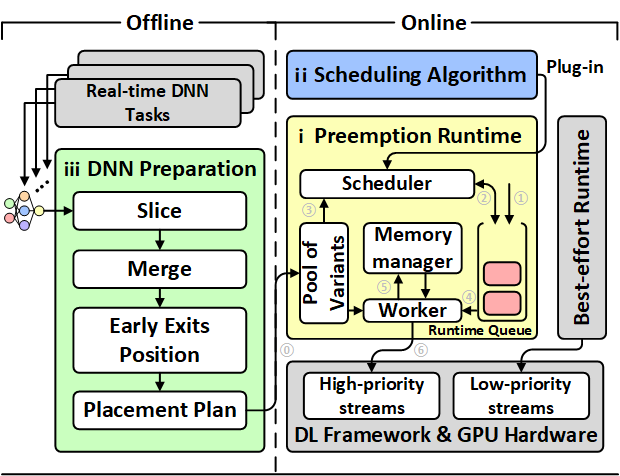
Figure 1: Overview of the Pantheon design.
1) Online module. This module is the core component for enabling preemptive DNN inference. It includes our proposed (i) preemptive runtime framework, which consists of a dedicated worker, memory manager, runtime queue, etc., as well as (ii) core preemptive task scheduling algorithm (§3.1). The runtime connects high-priority GPU streams to enable preemption between different real-time tasks. Consistent with existing work, low-priority streams are reserved for best-effort tasks. This online module can be installed as an intermediary layer between applications and the GPU backend without requiring modifications to its deep learning framework and the underlying GPU hardware and driver.
2) Offline module. This module contains two necessary (iii) pre- processing of the DNN to support preemption (§3.2), which is a one-time effort when the DNN is registered in the system.
Evaluation
We first examine the deadline miss rate and accuracy achieved by each method on three mobile edge application involving nine DNN tasks.
Deadline miss rate. From Figure 2(a), we can see that for concurrent DNN tasks, the classical real-time scheduling methods RMS and DMS become much less effective, leading to high deadline miss rates. RT-mDL can perform model scaling and execution scheduling to better accommodate multiple DNN tasks and significantly improve the deadline miss rate compared with RMS and DMS. However, due to its non-preemptive nature, RT-mDL can be affected by workload dynamics, which in turn could compromise the predefined schedule and result in missed deadlines. In contrast, Pantheon leverages preemption and can further reduce deadline miss rate to 0.39–1.10% in three applications, outperforming RMS, DMS, and RT-mDL by 92.51–98.98%, respectively.
Accuracy. As real-time task output that misses the deadline becomes invalid, the accuracy of a job is counted as zero if it misses the deadline. Thus, the accuracy of RMS and DMS is relatively low in Figure 2(b) due to their high deadline miss rates. RT-mDL significantly surpasses RMS and DMS in accuracy, while Pantheon can achieve even higher accuracy than RT-mDL in all three applications. Overall, Pantheon improves the accuracy by 69.1–154.8%, 174.7–315.5% and 2.2–46.0% compared to RMS, DMS, and RT-mDL, respectively
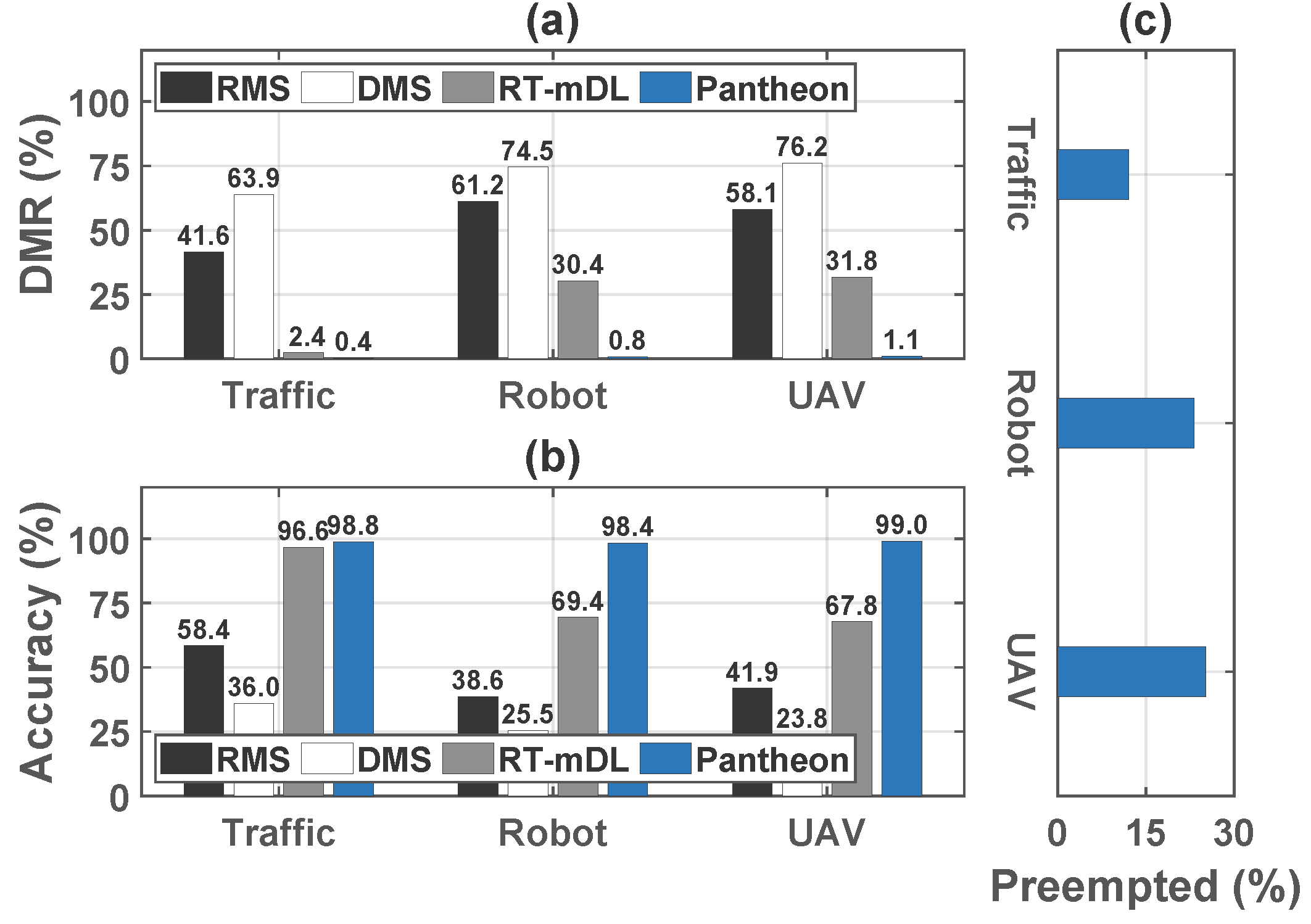
Figure 2: a) DMR and (b) accuracy achieved by each method. (c) Ratio of the preempted jobs over the total number of jobs executed.
To further delve into the performance gains of Pantheon, we count how often the preemption occurs in Figure 9(c). In the traffic application, the workload of DNN tasks is relatively lower than other two applications, and about 12% jobs need to be preempted, which already leads to substantial performance gains achieved by Pantheon than other methods. As the need of preemption further increases, more performance gains are obtained in Figure 9, indicating the efficacy of the Pantheon design.
Conclusion
This paper introduces Pantheon, a new preemption design for multi-DNN inference in mobile edge GPUs. The design of Pantheon reveals that the two-tier GPU stream prioritization available on mobile edge devices is adequate to enable such services. These two tiers of priorities are primarily used to distinguish between real-time and best-effort tasks. Preemption between real-time tasks, whose priorities change over time, can be further achieved through software design. This includes an online runtime with comprehensive preemption logic and innovative scheduling, and offline DNN processing. Pantheon does not need to modify deep learning frameworks and GPU drivers, making it easy to deploy. Extensive experiments show significant improvements in system performance compared to state-of-the-art methods.